PICNIC
I spent last week in Amsterdam at the PICNIC conference. Vlad Trifa of SAP/ETH invited me to present at an Internet of Things special session he organized, and it was one of the highlights of the conference. His timing was impeccable, with the session arriving just days after Cisco's Internet of Things consortium (IPSO Alliance) announcement (which, tangentially, now canonizes that term as yet another name for ubiquitous computing, though, as a term, you could certainly do worse and you could argue that it's the sub-1m granularity of ubicomp). It was great to share the tiny cafe stage with folks representing a wide range of organizations from giant conglomerates and emerging players to other fledgling startups.
I gave a talk entitled Shadows and Manifestations (440K PDF) (Matt Jones has posted a video of the talk on Vimeo--thanks Matt!) that focused on several of the ways I've been thinking about ubicomp UX design (and, by extension, Internet of Things UX design). If you've collected the whole set, there's little that's totally new. I have expanded my thinking on information processing is a material with some historical parallels to other materials and I have included some newer thinking about the implications of digital identification technology and ubicomp.
The most interesting result of the session for me was the high degree of similarity between the various ideas. This could just be a product of Vlad's curatorial process, but there were uncanny resonances between a number of the ideas in the presentation, and many ideas came up repeatedly. My presentation was roughly in the middle of the session, and I spent the whole first half frantically updating my slides in response to what others were saying. It was clear that in this group it wasn't necessary to talk in detail about ubicomp as an emergent property of the economics of CPU prices, that devices become intimately coupled with services, or that networks of smart things generate whole new universes of services.
The Internet of Things and Directories
One of the ideas that emerged in multiple presentations in conversations is for a device information brokerage and translation service. The idea is that a central service brings together information generated by all of these smart devices in a standard way and in a predictable location to facilitate mashups between various devices. Violet, tikitag, OpenSpime and Pachube, all of whom were represented, all essentially share this idea.
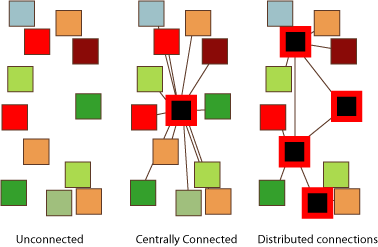
This got me thinking about other such systems I've seen, and I realized that I've seen this pattern before at least twice before: in Internet hostname resolution and P2P file sharing. For host resolution, before DNS there was HOSTS.TXT, a canonical file that stored all of the addresses of all the computers on the Internet. Eventually, this became untenable and the distributed system we know today was devised. In DNS there is no single central authority, but distributed authorities and protocols that extracts the canonical answer from a web of connections. Similarly, the P2P file sharing world started with Napster, which had a single server (or service) that knew where all the files were and redirected various queries in a top-down way. However, the deficiencies in that approach gave way to the distributed indexes of Gnutella. We're now seeing the same thing with BitTorrent, which relies on trackers to connect someone who has data and someone who wants it, but is moving a distributed trackerless model.
The unifying pattern here is:
- Create a service that runs on a number of devices
- Create a central phonebook so that those devices can find each other
- Create a distributed phonebook that is as distributed as the devices it indexes
Now the question becomes: what happens between steps 2 and 3? Why is there a repeated emergent pattern that such go through? I have a theory in two parts:
- A crisis happens if the service is successful. The centralized server model becomes too resource-constrained (i.e. it's overloaded beyond a "reasonable" cost of upgrading).
- This is a necessary evolution. Systems that start out with distributed indexes are significantly more complex than centralized ones. This requires a lot of implementation overhead on the part of the server and device designers and is brittle because it assumes feature priorities that may not match actual needs. In other words, if there isn't a perceived need, people don't want to write a bunch of code for scaling a service they aren't sure about. Moreover, it's not clear what the system should do, and initial assumptions are notoriously error-prone. I've seen a number of protocols that attempt to abstract a problem before it's clear what the problem is.
Google Protocol Buffers as a device communication standard
Finally, this made me think back to a discussion I started having with Bjoern, Tod and some of the other Sketching folks, which is the use of Google's new Protocol Buffers as a meta-protocol for devices to speak to each other. The point of Protocol Buffers is that they are simultaneously flexible and lightweight, which is valuable both when you're moving huge amounts of data around AND when you have very little processing power.
Google lists as advantages that:
- [Protocol buffers] are simpler
- are 3 to 10 times smaller
- are 20 to 100 times faster
- are less ambiguous
- generate data access classes that are easier to use programmatically
Google uses them to reduce the amount of code they have to throw around between services on the back end, but I thought that this describes many of the same constraints that small devices have. So my (super nerdy, sorry designers) question for all of the folks working on brokerage services: why not support/encourage the use of Protocol Buffers as the preferred format-independent data interchange mechanism?
[Tangentially, "Protocol Buffers" is a terrible name; it is simultaneously generic and overly specific and I think that the name will significantly hurt its adoption.]